 Tweet
Tweet
It is now possible to import the National Software Reference Library (NSRL) data set as a hash database in OSForensics.
Background
From the NSRL's web site.
"The National Software Reference Library (NSRL) is designed to collect software from various sources and incorporate file profiles computed from this software into a Reference Data Set (RDS) of information. The RDS can be used by law enforcement, government, and industry organizations to review files on a computer by matching file profiles in the RDS. This will help alleviate much of the effort involved in determining which files are important as evidence on computers or file systems that have been seized as part of criminal investigations."
The RDS is in text format, which makes it slow to search. But it is now possible to import the whole set into OSForensics for fast searching. Once imported the entire set can be searched within a second. You can also browse the entire set as a tree view and extract portions of the set into new hash set databases.
Import process
The import process is detailed in the OSF help file. But reproduced here,
1. Download the dataset from http://www.nsrl.nist.gov/. Currently the dataset is distributed as a set of four .iso files. To access the contents of these files you will either need to burn them to DVD or mount them using a virtual disk manager such as OSFMount.
2. On each of the disks is a zip file, each of these zip files must be unzipped into a sperate folder in the same location. For example, you create a folder named "NSRLData" and then under that folder you create folders named "Disk1", "Disk2" etc. in which you extract the zip files from each disk.
3. Create a new empty database in OSForensics, you may import to a non empty database but this is not recommended.
4. Make the new database active.
5. Select the "NSRL Import.." button on the hash management window and then select the root folder for all the unzipped sub folders. (the "NSRLData" folder in the example from step 2).
Import duration
Note this process can take a very long time to complete, up to several days on some systems. One way to make the process more manageable is to only import a disk at a time. This would mean in step 2 above you would only extract one of the zips, then remove it and extract the next and repeat the process importing into the same database. This is one scenario where importing to a non-empty database is recommended. This will actually take more time total but breaks the task up into shorter steps. You can also back-up the database in between each import in case an error occurs this way.
Another way to speed up the process is to make sure the database is on a solid state hard drive of a RAM drive. Import time is highly dependent on the random seek read/write performance of the drive. On an average system with a normal hard drive the process takes about 50 hours. On a RAM drive the process has been seen to take as little as 10-15. A solid state drive will likely have a import time somewhere between these two figures.
Data set size
The December 2010 release is made up of 4 CDs (4 x 378MB = 1.5GB). Each of which contain compressed data. When uncompressed the data set is 7.2GB of comma separated text. Within this data set is information and hashes for over 62 million files and almost 19 million SHA-1 values.
Once the 4 discs are imported, and indexes added to the data, the uncompressed size is approximately 9.8GB. This includes both the MD5 and SHA1 hash values. Not all tools import both hash values, but OSF does.
User interface
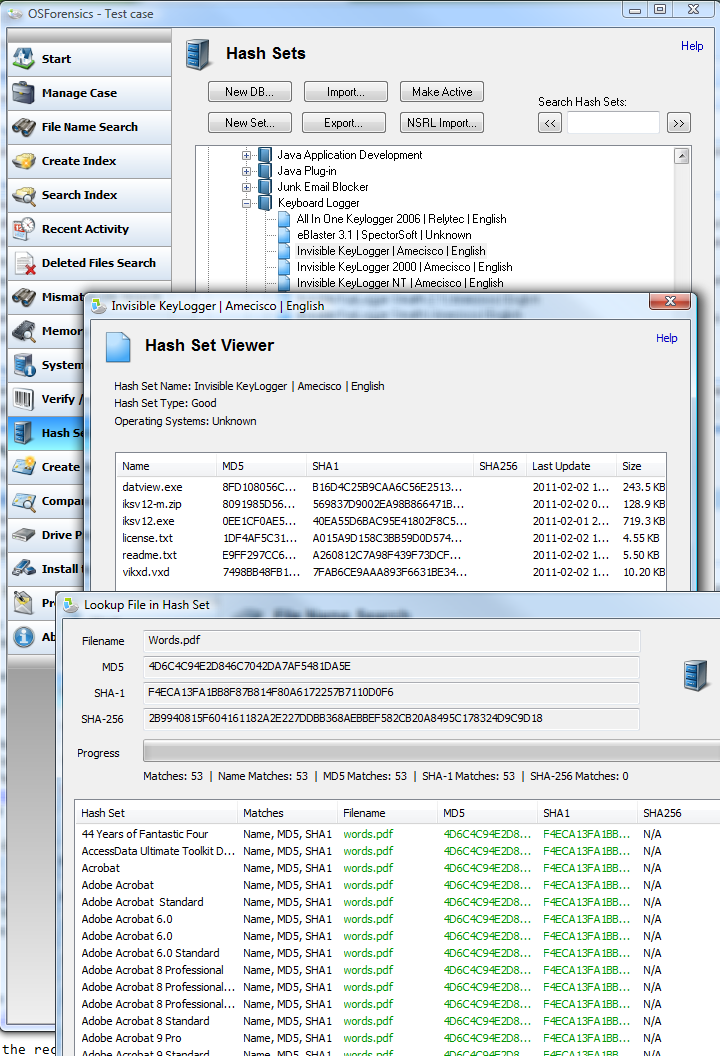
Background
From the NSRL's web site.
"The National Software Reference Library (NSRL) is designed to collect software from various sources and incorporate file profiles computed from this software into a Reference Data Set (RDS) of information. The RDS can be used by law enforcement, government, and industry organizations to review files on a computer by matching file profiles in the RDS. This will help alleviate much of the effort involved in determining which files are important as evidence on computers or file systems that have been seized as part of criminal investigations."
The RDS is in text format, which makes it slow to search. But it is now possible to import the whole set into OSForensics for fast searching. Once imported the entire set can be searched within a second. You can also browse the entire set as a tree view and extract portions of the set into new hash set databases.
Import process
The import process is detailed in the OSF help file. But reproduced here,
1. Download the dataset from http://www.nsrl.nist.gov/. Currently the dataset is distributed as a set of four .iso files. To access the contents of these files you will either need to burn them to DVD or mount them using a virtual disk manager such as OSFMount.
2. On each of the disks is a zip file, each of these zip files must be unzipped into a sperate folder in the same location. For example, you create a folder named "NSRLData" and then under that folder you create folders named "Disk1", "Disk2" etc. in which you extract the zip files from each disk.
3. Create a new empty database in OSForensics, you may import to a non empty database but this is not recommended.
4. Make the new database active.
5. Select the "NSRL Import.." button on the hash management window and then select the root folder for all the unzipped sub folders. (the "NSRLData" folder in the example from step 2).
Import duration
Note this process can take a very long time to complete, up to several days on some systems. One way to make the process more manageable is to only import a disk at a time. This would mean in step 2 above you would only extract one of the zips, then remove it and extract the next and repeat the process importing into the same database. This is one scenario where importing to a non-empty database is recommended. This will actually take more time total but breaks the task up into shorter steps. You can also back-up the database in between each import in case an error occurs this way.
Another way to speed up the process is to make sure the database is on a solid state hard drive of a RAM drive. Import time is highly dependent on the random seek read/write performance of the drive. On an average system with a normal hard drive the process takes about 50 hours. On a RAM drive the process has been seen to take as little as 10-15. A solid state drive will likely have a import time somewhere between these two figures.
Data set size
The December 2010 release is made up of 4 CDs (4 x 378MB = 1.5GB). Each of which contain compressed data. When uncompressed the data set is 7.2GB of comma separated text. Within this data set is information and hashes for over 62 million files and almost 19 million SHA-1 values.
Once the 4 discs are imported, and indexes added to the data, the uncompressed size is approximately 9.8GB. This includes both the MD5 and SHA1 hash values. Not all tools import both hash values, but OSF does.
User interface